
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 서비스기획
- 자바스크립트
- 프로젝트 매니저
- kpt회고
- 코딩
- 데이터분석
- UX
- 스프링
- tag
- 쇼핑몰
- 서비스분석
- 서비스 기획자
- 회고록
- javascript
- 데이터
- jquery
- 생활코딩
- 스프링부트
- 서비스 기획
- PO
- 회고
- CSS
- 코드스테이츠
- 프로덕트 매니저
- PM부트캠프
- db
- SpringBoot
- PM
- html
- UI
- Today
- Total
콘텐츠기획자의 IT입문서
Spring Data JPA & 데이터베이스 CRUD 및 Paging 본문
데이터베이스를 활용하기 위해서는 반드시 Spring Data JPA가 필요하다.
프로젝트 생성시 Dependencies에 추가하여 다운받는 것이 좋다!


ORM과 JPA
ORM (Object Relational Mapping)
- 객체지향 패러다임을 관계형 데이터베이스에 보존하는 기술.
객체지향과 관계형 데이터베이스는 유사한 특징을 지닌다.
- 객체지향에서는 클래스에서 인스턴스를 생성하여 인스턴스라는 공간에 데이터를 보관하고,
관계형 데이터베이스의 테이블에서는 하나의 Row(레코드, 튜플)에 데이터를 저장한다. - 둘의 차이점은 '객체'는 데이터+행위(메서드)라면, 'Row'는 데이터 개체(entity)만을 의미한다.
이러한 특징에 기초한 ORM은 객체지향을 자동으로 관계형 데이터베이스에 맞게 처리해주는 기법이다.

JPA (Java Persistence API)
- 자바 ORM 기술에 대한 표준 명세. (자바에서 제공하는 API)
- 자바 어플리케이션에서 관계형 데이터베이스를 사용하는 방식을 정의한 인터페이스. (라이브러리X)
- ORM이기 때문에 자바 클래스와 DB테이블을 매핑한다. (SQL을 매핑X)
- JPA는 단순한 스펙이므로 해당 스펙을 구현하는 구현체마다 회사의 이름이나 프레임워크의 이름이 다르다.
스프링 부트는 여러 JPA의 구현체 중 Hibernate를 이용한다.
Hibernate : ORM을 지원하는 오픈소스 프레임워크.
단독으로 프로젝트에 적용이 가능한 독립된 프레임워크로, 스프링에서도 Hibernate와 연동해서 JPA를 사용할 수 있음.
JDBC
JDBC는 DB에 접근할 수 있도록 자바에서 제공하는 API.
모든 자바 Data Access 기술의 근간으로, 모든 Persistance Framework는 내부적으로 JDBC API를 이용한다.
데이터베이스를 위한 스프링 부트 설정
Maven 저장소에서 MariaDB 관련 드라이버를 선택하여 Gradle 설정을 복사,
프로젝트 내 gradle.build 파일의 dependencies 항목에 추가한다. (Gradle Refresh를 하여 라이브러리의 변경을 반영.)
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-web'
compileOnly 'org.projectlombok:lombok'
developmentOnly 'org.springframework.boot:spring-boot-devtools'
annotationProcessor 'org.projectlombok:lombok'
providedRuntime 'org.springframework.boot:spring-boot-starter-tomcat'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
// https://mvnrepository.com/artifact/org.mariadb.jdbc/mariadb-java-client
implementation group: 'org.mariadb.jdbc', name: 'mariadb-java-client', version: '2.7.4'
}
스프링 프로젝트의 데이터 베이스 설정
application.properties파일 내 내용 추가
spring.datasource.driver-Class-Name=org.mariadb.jdbc.Driver
spring.datasource.url=jdbc:mariadb://localhost:3306/bootex
spring.datasource.username=bootuser
spring.datasource.password=bootuser
//JPA관련 내용
spring.jpa.hibernate.ddl-auto=update
spring.jpa.properties.hibernate.format_sql=true
spring.jpa.show-sql=true

- spring.jpa.hibernate.ddl-auto
: 프로젝트 실행 시 자동으로 DDL(create, alter, drop 등)을 생성할 것인지 결정.
(create : 매번 새로 테이블 생성 / update : 테이블이 없으면 create, 변경이 필요하면 alter로 작동) - spring.jpa.properties.hibernate.format_sql
: Hibernate가 동작하면서 발생하는 SQL을 가독성 있게 포맷팅해서 출력. - spring.jpa.show-sql
: JPA 처리 시 발생하는 SQL을 보여줄지 말지 결정.
[참고] https://lannstark.tistory.com/14
프로젝트 실행
프로젝트를 실행하면 실행되는 로그에 'HikariPool'로 시작하는 부분이 있다.
스프링 부트가 기본적으로 이용하는 커넥션 풀이 HikariCP 라이브러리를 이용하기 때문.
* 커넥션 풀이란?
Pool에 데이터베이스와의 연결(=커넥션)들을 미리 만들어 두고 데이터베이스에 접근시 풀에 남아있는 커넥션중 하나를 받아와서 사용한뒤 반환하는 기법.

웹 애플리케이션의 경우 다수의 사용자가 데이터베이스에 접근해야 하는 상황이 생겼을때
사용자들이 요청할때마다 연결을 만들고 해제하는 과정을 진행하면 비효율적이다.
따라서 커넥션풀을 이용하여 필요한 사용자가 요청시 미리 만들어 놓은 연결을 주는 형식인 커넥션풀이 효과적이다.
Spring Data JPA 개발에 필요한 것

- Entity 클래스 : JPA를 통해 관리하게 되는 객체(Entity Object)를 위함.
package org.zerock.ex2.entity; import lombok.*; import javax.persistence.*; @Entity @Table(name="memo_tbl") @ToString @Getter @Builder @AllArgsConstructor @NoArgsConstructor public class MemoEntity { //entity class로 데이터베이스의 테이블과 같은 구조로 작성 @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long no; @Column(length=200, nullable = false) private String text; }
@Entity : 클래스의 인스턴스들이 JPA로 관리되는 엔티티 객체라는 것을 의미.
@Table : 엔티티 클래스를 어떤 테이블로 생성할 것인지에 대한 정보(테이블명, 인덱스 등). @Entity 와 함께 사용할 수 있다.
@ToString : ToString() 메소드를 자동 생성해줌.
@Getter : Getter() 메소드 생성
@Builder : 객체를 생성할 수 있도록 처리.
@AllArgsConstructor (생성자 자동 생성), @NoArgsConstructor (매개변수를 받지 않는 생성자 생성)와 항상 함께 사용.
@Id : Primary Key에 해당하는 특정 필드를 지정해주기 위함.
@GeneratedValue : Primary Key를 자동으로 생성하고자 할때 사용.
GenerationType
AUTO : JPA 구현체인 Hibernate가 생성방식을 결정. (default)
IDENTITY : 사용하는 DB가 키 생성을 결정. (MariaDB의 경우 auto increment 방식 이용)
SEQUENCE : DB의 시퀀스를 이용해서 키를 생성. @SequenceGenerator와 함께 사용.
TABLE : 키 생성 전용 테이블을 생성해서 키를 생성. @TableGenerator와 함께 사용.
@Column : 추가적인 필드가 필요한 경우 사용. DB 칼럼에 필요한 정보 제공함. (주로 nullable, name, length 등)
반대로 DB 테이블에 칼럼으로 생성되지 않는 필드의 경우 @Transient 적용.
- Repository : Entity 객체들을 처리하는 기능을 가짐. 인터페이스로 정의해야 한다.
Spring Data JPA는 JPA 구현체인 Hibernate를 이용하기 위한 여러 API를 제공하는데,
그중 가장 많이 사용하는 것이 JpaRepository 인터페이스.
JpaRepository 인터페이스 선언만으로 자동으로 스프링의 빈(bean)으로 등록된다.
package org.zerock.ex2.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import org.zerock.ex2.entity.MemoEntity;
public interface MemoRepository extends JpaRepository<MemoEntity, Long> {
}- RepositoryTests -> SQL 없이 CRUD 작업 테스트!

데이터 생성
package org.zerock.ex2.repository;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.zerock.ex2.entity.MemoEntity;
import java.util.stream.IntStream;
@SpringBootTest
public class MemoRepositoryTests {
@Autowired
MemoRepository memoRepository;
@Test
public void testClass(){
IntStream.rangeClosed(1,50).forEach(i->{
MemoEntity memoEntity = MemoEntity.builder().text("Write no."+i).build();
memoRepository.save(memoEntity);
});
}
}@Autowired : 필요한 의존 객체의 타입에 해당하는 빈을 (생성자, Setter, 필드) 찾아 주입해줌.
testClass() : MemoRepository 인터페이스 타입의 실제 객체가 어떤것인지 확인하는 용도.
IntStream.rangeClosed() : 스트림 생성. (IntStream/LongStream, range()/rangeClosed())

JPA 메서드
insert 작업 : save(entity)
update 작업 : save(entity)
select 작업 : findById(key type), getOne(key type)
*findById()와 getOne()은 DB를 먼저 이용하는지 나중에 필요한 순간까지 미루는지, 데이터 실행 순서에 차이가 있음.
delete 작업 : deleteBy(key type), delete(enity)
데이터 조회
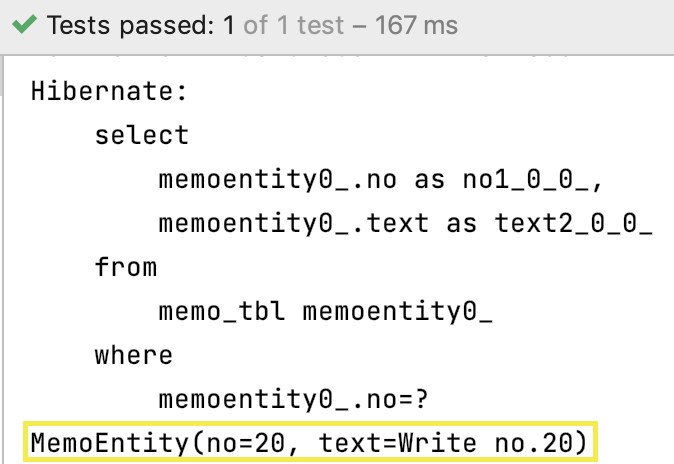
@Test
public void testSelect(){
Long no = 20L;
Optional<MemoEntity> result = memoRepository.findById(no);
if(result.isPresent()){
MemoEntity memoEntity = result.get();
System.out.println(memoEntity);
}
}
데이터 수정
@Test
public void testUpdate(){
MemoEntity memoEntity = MemoEntity.builder().no(50L).text("Changed!!").build();
System.out.println(memoRepository.save(memoEntity));
}
데이터 삭제
@Test
public void testDelete(){
Long no = 5L;
memoRepository.deleteById(no);
}
페이징 처리
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
@Test
public void testPageDefault(){
Pageable pageable = PageRequest.of(1,10);
Page<MemoEntity> result = memoRepository.findAll(pageable);
System.out.println(result);
}
limit : MariaDB에서 페이징 처리에 사용하는 구문.
count() : 전체 갯수를 처리하는 것.
정렬조건 추가
import org.springframework.data.domain.Sort;
@Test
public void testSort(){
Sort sort = Sort.by("no").descending();
Pageable pageable = PageRequest.of(0,10, sort);
Page<MemoEntity> result = memoRepository.findAll(pageable);
result.get().forEach(memoEntity -> {
System.out.println(memoEntity);
});
}
'Spring' 카테고리의 다른 글
| 맥북에서 파일경로 설정 (C드라이브, D드라이브) (0) | 2022.03.08 |
|---|---|
| Spring Data JPA - 쿼리 메서드 & @Query (0) | 2021.09.06 |
| Hello, Spring Boot! 프로젝트 실행하기 (0) | 2021.09.04 |
| Spring Boot 프로젝트 구성 및 생성하기! (0) | 2021.09.04 |
| Spring Boot / Spring이란? (0) | 2021.09.04 |



